Published on 02/08/2017 | Technology

This article is Part 2 of the whitepaper Digital Enterprise Architecture in Manufacturing , following from Part 1 here.
Data in models has been addressed before like e.g. in which proposes to have a separation of abstract model, concrete model and data. Whether this is the right approach is not clear yet. We focus on describing the requirements from a manufacturing point of view:
In the following data is characterized by data type and data ingestion: The different data types considered are: time series (like e.g. a flow of temperature or pressure measurements), transactional (like e.g. a relational database table), structured ad hoc (like e.g. excel files), unstructured (like e.g. text), binary (like e.g. images), and complex (i.e. a mix of all possible data types) data.
The different data ingestion methods considered are: continuous/ near real time (like e.g. a continuous stream of data), batch (like e.g. a bulk of data with a frequency of day or hour), or ad hoc (like e.g. applying some analysis results to a model).
Data can be connected to concepts and/or relationships in different annotations. In particular, a concept or a relationship of a model can be related to a single or a set of data points. Further a relationship may be related with a constraint to relate the data of the source and the target concept. Finally, a concept may be related to a query describing relevant data stored in a data storage somewhere. Based on these options the model annotations either can be particular values for an analysis or visualization or be a means to retrieve the data by using constraints or queries.
3.1. Decision Support
In the context of Industry 4.0 a manufacturing company wants to make all data of their systems and plants available in a data lake to increase data analysis efficiency. The data provided by these systems are ad hoc, transactional, and time series data, which are updated in a batch once an hour. The company is investigating various architecture options for implementing this change and is using a portfolio management approach to compare the different options based on KPI’s. The KPI’s are dependent on usage patterns of systems, data volumes maintained at the different plants, and the usage of analysis for different products or product groups.
To support the decision process by providing the right KPI values, the relevant metrics used by the KPI’s have to be calculated and imported from existing systems. The aim is to have this connection established in an automated way to redo the analysis on a regular basis. The motivation is to monitor and to validate the implementation process of the project beyond the decision making and to validate whether the higher analytics efficiency has been accomplished. By having the core data related to the model, the evolution of the model will influence the calculation of the KPI’s and will ensure the consistency of the calculation with the processes in the company.
For different data types, data ingestion and annotations there are very different requirements for relating the data to the model. In current tooling it seems mainly possible to add single values to concepts or relations, thus in general small amounts of structured data which are ad hoc ingested. However, when combing models with data and analysis new use cases can be considered.
3.2. Manual Root Cause Analysis
In a chemical plant multiple ingredients, provided by multiple suppliers, are mixed into a chemical product. The execution of the production process is usually controlled by a Manufacturing Execution System (MES), while the product quality results are entered into a Laboratory Information Management System (LIMS). The LIMS information is available only a few days after production of the product due to the duration of the chemical analysis.
The aim is to relate the MES and LIMS data and to give the user the possibility to investigate why a certain product had bad chemical test results. In this scenario, the MES and the LIMS data are transactional data and are provided in a batch fashion. The LIMS results can be associated with quality assurance step in the process model describing the production process in the model, while the MES data can be related to the physical layer of a model describing a production line as well as many step sin the production process. The model provides the relations and dependencies between physical layer and process model and therefore allows to investigate potential root causes by navigating the model. That is, the root cause of a bad test requires to look at historic MES data for a particular line, which is modelled on the physical layer of a model.
There are many specialized applications that manage information, concepts, and relationships between concepts, which should be related in a single model to enable the overall goals addressed in this paper. Managing the same concepts and relationships in two systems is not feasible, thus, there must be an import option for concepts and relationships.
This requires to find a mapping from the concepts and relations used in the external application to the expressiveness of the used model. The risks are that either the model in the external application is richer than the one in the model, or it is not expressive enough such that the import has to set default values for certain aspects of the model.
Another requirement is that model changes in an application are maintained as different versions on the integrated model instead of replacing it. Since the model provides the context for data and analysis results it is important to maintain each version of the context, thus the model. Further, it enables to derive the differences between two arbitrary versions of the model, which explicates changes related to the application.
As a final requirement the modelling tool should support round trip engineering, thus, make changes in the application, import it into the model, check e.g. consistency and change data in the application to make the application consistent with e.g. regulations. Such a round trip engineering requires that the model can be exported and be imported into the application.
4.1. Template based Deployment
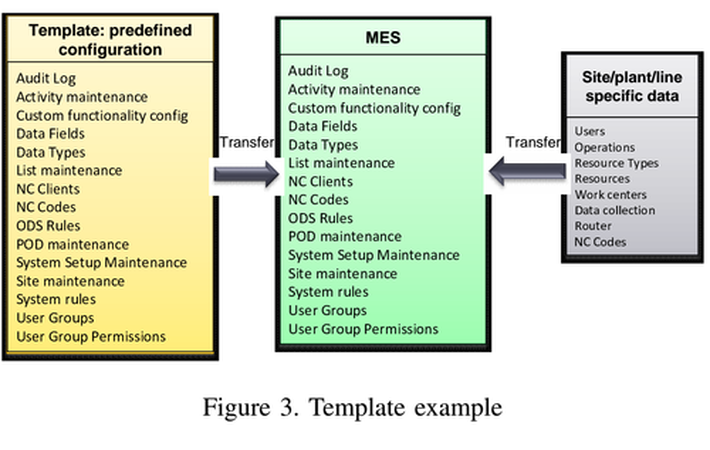
A manufacturer has 30 plants and is harmonizing the MES implementation in each plant to a single version of a specific MES. This requires that all the current configurations of the plant specific MES are translated into a new configuration for the target MES. The template consists out of a predefined configuration, which is shared with all plants, and a plant specific part. The evolution of templates is managed in a roadmap continuously modifying and enriching the template. The predefined configuration contains data related to error codes, user groups etc., while the plant specific part contains information about the actual users and their relation to user groups as well as product specific error codes (see Fig 3). A template is data, representing concepts and their relations, thus forms a model. In case the integration of MES with e.g. ERP is attempted, a model is beneficial to investigate the dependencies between the different applications. Thus, a model import and export is required to avoid maintaining the model in two places.
4.2. Master Data Management
As a follow up on the previous example, managing the data related to the templates is a form of Master Data Management (MDM). In this example, the data currently is maintained in an Excel sheet and then imported into the individual plant MES. This approach has the disadvantage that dependencies between concepts, like e.g. availability of a user group for a particular user, are not checked, but result in errors after the data has been imported into the MES. Further, the data in the MES are modified in the MES directly after the import, thus the MDM Excel sheet is not the master anymore. An alternative is to manage the master data in the model itself, while supporting an export to Excel for fast entry or modification of values, and providing an export to the MES. After changes of the model in the Excel sheet, the model is updated. The same round trip is also possible with a MES. This way the model checks consistency before the import to the MES and the import of modified data from the MES into the model allows to keep the model up to date with the operational MES. The concept is visualized in Fig 4.
4.3. Integrating Process Mining Results
In discrete industry a manufacture has implemented a new material distribution approach in an MES, however, the implementation was not working properly and the reasons for that were unknown. The implementation was described as a process model and process mining has been used to generate a model from MES data. An example process mining result is depicted in Fig 5. The rectangles represent activities in a process, while the arrows represents a follows relationship. The process mining model and the manually created process model are then related with each other, thus analysis is performed on the compliance or consistency of the derived and manually created model. It reveals implementation, data collections, and manual modelling issues. Based on these three cases, the variety of of potential systems to provide a workflow model for import and/or export is high and requires quite some effort per system. However, the import/export capabilities are re-usable for several customers and therefore should be addressed in a community effort.
We have used Archimate version 3.0 as the EA language for our investigation. The main reason for this choice is that the EA language was recently extended by a physical layer. For manufacturing companies the physical layer, i.e. shop-floor, physical machines, raw materials, products, and finished goods are important assets and have a strong relation to OT and IT applications and processes.
We have investigated to which extend the extension is sufficient to address manufacturing requirements. In particular, it got evaluated to which extend Archimate version 3.0 can represent the relations between objects in ANSI/ISA-95 (alternatively, ISO/IEC 62264). ISA-95 is the standard of the manufacturing industry to describe the exchange of information between OT and IT layer. The investigation showed that very little relations in ISA-95 can be directly mapped to Archimate. However, patterns have been identified to cover 96% of the ISA-95 relations.
The remaining relations will require adjustments in the Archimate language. For example, modelling a Bill Of Material (BOM): A BOM is a central data object in manufacturing processes and their relation with other systems like e.g. ERP. Modelling the BOM as a business object or as a material on the physical layer? Physical object often have a duality: they exist in the physical world but they also have a digital representation in IT applications. Understanding and representing this duality is one of the mayor challenges.
An advantage of ISA-95 is that it is well known in the manufacturing world. It is often used as a reference model for describing functions of processes and applications in an organization. It is a semantic framework. Since the model gets really huge and users add their own labels to concepts, it will be very difficult to identify the right concepts in a model providing a certain functionality. In our cases we have associated the concepts introduced by the users with the concepts in ISA-95 to provide a semantic mapping, which supports the access to the model for a larger user group.
Another challenge when working with the models was the management of perspectives of a process and handling the different versions. In our use cases we have used plateaus of Archimate to annotate concepts and relations belonging to a version or a perspective. Manually managing the relations of concepts and relations to a version or a perspective was not only very cumbersome and error prone, but resulted in very complex and hard to understand hierarchical plateau concepts. The challenge here is to find a good way in the modelling language to relate concepts and relations which are related to a higher semantic concept.
Finally, we observed that in order to do analysis the model has to be very homogeneous, i.e., process, application, infrastructure, or physical constructs have to be modeled always in the same way. Otherwise, the analysis has to consider all possible model approaches for a particular construct to correctly analyze the model. This means the architects creating the model must have a common understanding on how to model certain constructs. Thus, they have to agree on model patterns and use them accordingly. The availability of model patterns also allows to check for the consistent application of them in the model, which increases the consistency of the model and therefore the value for the subsequent analysis.
Read Part 3 of the article here.