Published on 11/07/2016 | Technology

Gaining attention largely due to the rise of the Internet of Things (IoT) and Machine Learning solutions, Predictive Maintenance brings new data and analytic capabilities to an age-old problem. How do we optimize the productivity of an asset? By enriching operational data with additional context such as environmental information and workload data and then applying analytic models, we can predict the risk of failure of assets at a point in time and do so in an automated manner that scales to millions of devices. This allows to reduce outages, maintenance costs, and impacts to customers, all contributing to a better quality of service.
Predictive Maintenance is a defect inspection strategy that uses indicators to prepare for future problems and as such it’s a response to the need to be ever more precise in maintenance management by applying data, context, and analytics (machine learning) to the problem space. There are many scenarios where Predictive Maintenance can be crucial, such as:
In Manufacturing is highly used to predict vehicle component outages and notify drivers and service technicians or to predict outages in the assembly line process;
In Utilities it is commonly used to predict outages in power generation equipment, with huge impact in quality of service and maintenance costs;
In Oil and Gas industry, it has been used to develop custom and optimal maintenance schedules for expensive assets such as submersible oil pumps;
In Public Sector it can be used to balance maintenance services based on citizen usage patterns of services, among many others.
From a business perspective, Predictive Maintenance plays a key role for different business decision-makers: for a COO, that owns the core operational metrics and is ultimately responsible for operational continuity, for a CFO, who will be attracted by the prospect of a reduction in costly unplanned outages, but also by the promise of OpEx savings , or even for a CMO, that cares about customer satisfaction and retaining revenue, as well as trust and reputation.
As an example, in this recent case, by using Microsoft Azure Machine Learning service, ThyssenKrupp has achieved an unprecedented view into elevator operations and maintenance, now and in the future. The system contains an intelligent information loop: data from elevators is fed into dynamic predictive models, which continually update datasets via seamless integration with Azure. With this, the elevators can actually teach technicians how to fix them, resulting in dramatically increased elevator uptime.
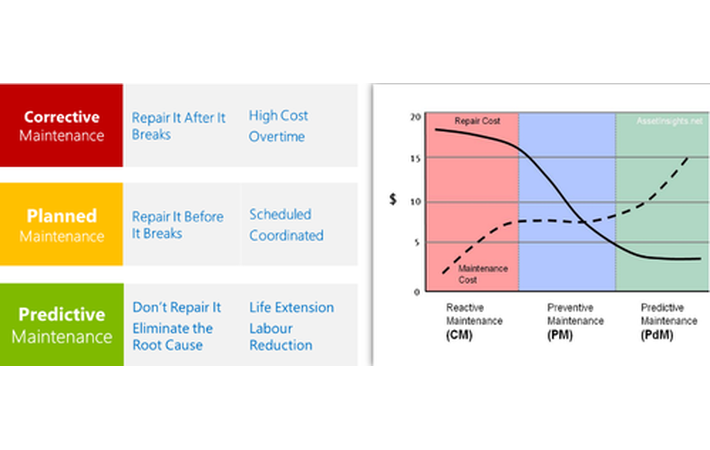
Maintenance costs are one of the largest factors impacting companies’ budget. Attempts to reduce these costs have led to the development of several maintenance strategies and solutions along time. The three basic maintenance policies include:
Corrective Maintenance implies the equipment is repaired after a failure has occurred. As long as an equipment is under a warranty agreement, the equipment owner does not usually pay for the repair though he can experience an unexpected malfunction.
Most equipment is also subject to a Preventive Maintenance policy, which requires performing periodic inspections and other operations at a schedule predetermined by the manufacturer, mostly on the basis of time in service. However, this policy does not take into account the actual condition of the equipment as it's scheduled at a fixed time interval.
In contrast, Predictive Maintenance can schedule an intervention based on some sensory information representing the current condition of the equipment and its subsystems and a probabiliy of failure. This approach should, on one hand, minimize the risk of unexpected failures, which may occur before the next periodic maintenance operation, and on the other hand, reduce the amount of unnecessary preventive maintenance activities.
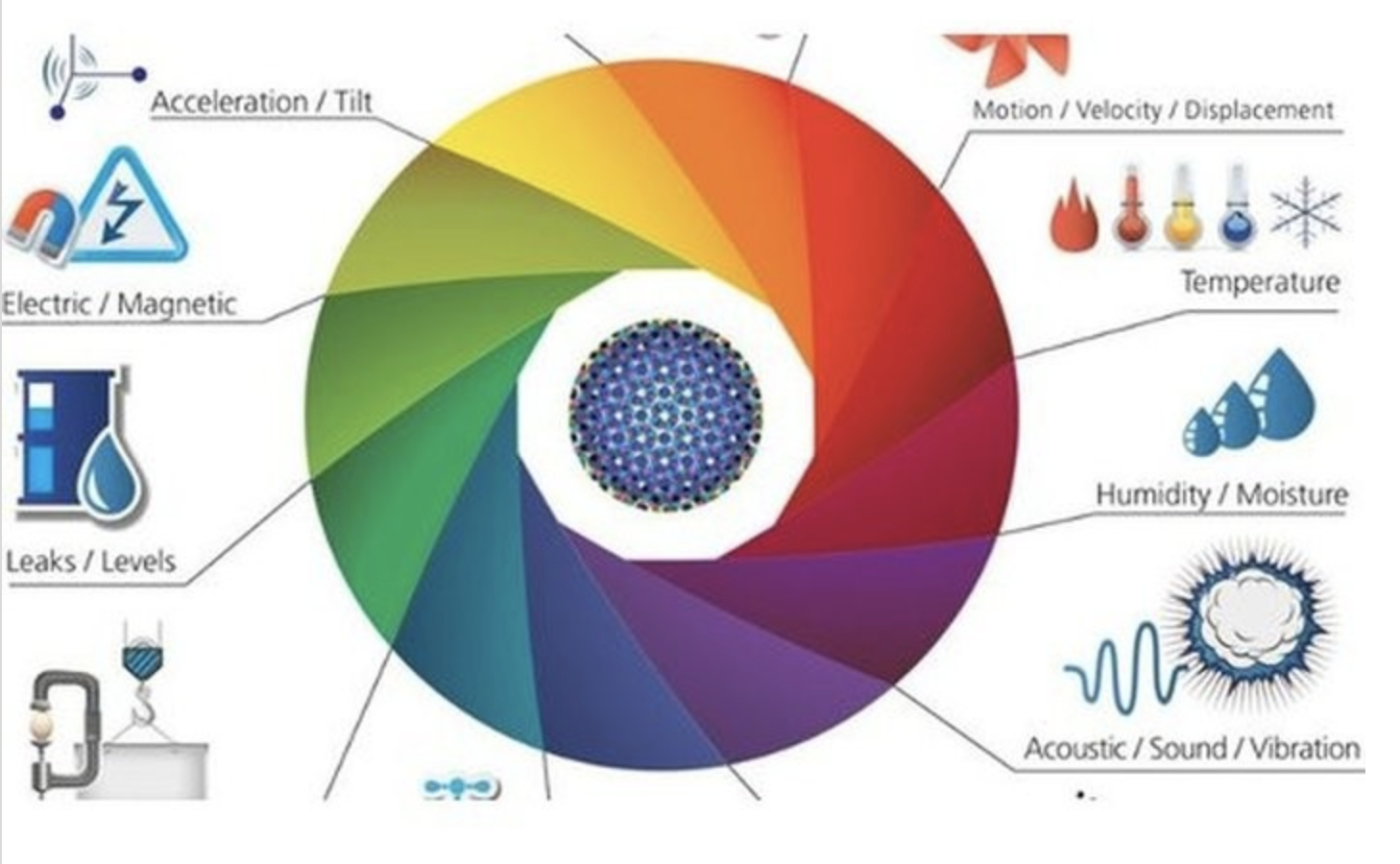
As time maintenance is not enough, context of use is required, which is where the analytics come in, aiming to “predict” risk of failure for devices with heavy use. It starts by a statistical model that gets better and better (trained) the more information you provide it. This requires the capability to understand reliability of equipment's at any point in time, to identify and isolate potential failures before they occur; to predict and plan for scheduled maintenance and downtime and to reduce unnecessary time-based maintenance operations. In order to do this, organizations need to have four things:
1. Rich Device Data: In order to predict and influence a equipment’s risk of failure, there must be sufficient data on historical behavior to support prediction. The definition of “sufficient” will vary by industry and context, but in general, the more transactions you can see, and the more rich the information associated with those transactions is, the better your ability to predict will be. That data then needs to be coordinated with metadata (info about channels, prices, locations, etc.) to create a single equipment view.
2. Flexible Analysis Environment: An analytics solution can be built incrementally as business needs warrant and allows an increasing range of analytical capabilities to be brought to bear to support maintenance efforts. One key service that will be immediately valuable is Azure Machine Learning, which can be applied against the single equipment view to score the risk of failure at a point in time. These scores can be combined with other equipment context to develop notifications and recommended actions for operations and service staff to take action on.
3. Ability to Take Action: Existing production work flow such as dashboards, command centers, and technician portals need to be instrumented to receive notifications and to record the actions taken (or not) based on those notifications.
4. Operations Feedback Loop: Once models and recommended actions are created in the analytics environment, their effectiveness needs to be tested. As equipment data connections are already enabled, additional connections to the data representing the action taken need to be developed. Then the actual outages can be compared to others to calculate the accuracy and efficacy of the model, notifications, and resulting actions. The results of all tests can be fed back into the analysis environment to allow optimization of the models.
As part of the Azure Machine Learning offering, Microsoft also provides a template that helps data scientists easily build and deploy predictive maintenance solutions, that can found on this public ML Models Gallery.
This predictive maintenance template focuses on the techniques used to predict when an in-service machine will fail, so that maintenance can be planned in advance. The template includes a collection of pre-configured machine learning modules, as well as custom R scripts, to enable an end-to-end solution from data processing to deploying of the machine learning model. Below you can see an overall data processing flow:
Three modeling solutions are provided in this template to accomplish the following tasks:
Regression: Predict the Remaining Useful Life (RUL), or Time to Failure (TTF).
Binary classification: Predict if an asset will fail within certain time frame (e.g. days).
Multi-class classification: Predict if an asset will fail in different time windows: E.g., fails in window [1, w0] days; fails in the window [w0+1,w1] days; not fail within w1 days
The time units mentioned above can be replaced by working hours, cycles, mileage, transactions, etc., based on the actual scenario.
This template uses the example of simulated aircraft engine run-to-failure events to demonstrate the predictive maintenance modeling process. The implicit assumption of modeling data as done below is that the asset of interest has a progressing degradation pattern, which is reflected in the asset's sensor measurements. By examining the asset's sensor values over time, the machine learning algorithm can learn the relationship between the sensor values and changes in sensor values to the historical failures in order to predict failures in the future.
A detailed explanation with all details for each step can be found here.