Published on 11/11/2016 | Market Sizing

Over the past five years, applications have undergone a paradigm shift. They now require more agility, scalability, and availability. The key trends in this era are driven by the use of social platforms, mobile devices, and software as a service (SaaS). Being able to ingest large amounts of data from various sources, and process it in real-time to deliver contextual information or business insights is a major competitive advantage.
To meet these new application requirements, organizations are forced to look beyond traditional relational databases. This has resulted in a slew of new database systems that are distributed and scale-out in nature, can be deployed on commodity hardware and offer tunable consistency vs. performance tradeoffs. It’s important to note that to cater to the agility requirements, the database-as-a-service model in the cloud is being adopted as well.
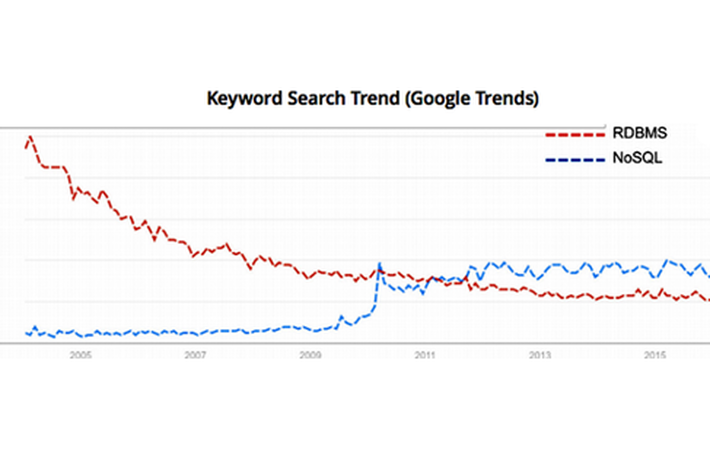
To show just how big the shift to distributed databases is, below is a keyword search trend graph showing the sharp rise in NoSQL search.
The implication in all of this is that requirements for data protection have changed forever, driven by this data-centric world (web-scale applications and distributed databases). Organizations are collecting vast amounts of data and seek to drive more value from that data to make better and faster business decisions. Most distributed and cloud databases already provide replication capability and thus satisfy the availability requirements of data protection. However, data protection requirements for scalable point-in-time backup and recovery need to be addressed. Without point-in-time backups, organizations are at substantial risk of losing data due to human error, logical corruption, and other operational failures. Traditional backup solutions were built to address the requirements of relational databases that used shared storage and had the ACID transaction model. Unfortunately, they fall well short in addressing the point-in-time backup requirements of distributed databases (local storage, eventual consistency, and the elastic nature of infrastructure).
As database architecture has fundamentally changed to meet new application requirements, data protection needs to be redefined and re-architected as well. The following are the new requirements for data protection.
Take a durable point-in-time backup copy of an eventually consistent database, we call it “versioning” the new paradigm of data protection for this new distributed era: backups to snapshots to replication to copy data management to versioning.
- Minimize time to recover from failures (low RTO).
- Scale with the growing needs of the application.
- Enable easy refresh of test/dev environments for continuous development.
- Provide operational resiliency in event of failures.
- Provide deployment flexibility in public cloud or on-premise datacenter.
Most organizations are investing in enterprise-grade point-in-time backup and recovery products so they may deploy and scale their next-generation application on distributed databases with confidence. In the next five years, it will be exciting to watch companies redefine the data protection technologies to meet the requirements of next-generation applications.
This article has been reproduced with permission from Ms Jeannie Liou.
The original article can be found here.